Weakly-Supervised Localization: 뉴럴넷은 어디를 바라보고 있는가
ConvNet이 이미지를 다루는 데 강력한 성능을 보이기는 하지만, layer가 깊어지면 깊어질수록 이미지의 어떤 특징을 보고 판단을 내리는지를 파악하기란 쉽지 않다.
이미지 하나를 인풋으로 넣고 layer를 차례차례 통과하면서 activation이 어떻게 변하는지를 살펴볼 수도 있겠지만 VGG와 같은 모형처럼 레이어가 매우 깊어지거나 GoogLeNet, ResNet처럼 특수한 모듈 구조를 사용, 또는 residual connection을 사용하는 네트워크에서는 뉴럴넷이 이미지의 어느 부분을 중요하게 생각하는지의 정보를 얻기가 힘들어진다.
블랙박스인 듯 보이는 뉴럴넷(특히 ConvNet)의 내부를 조금이나마 투명하게 드러내려는 시도는 꾸준히 있어왔다. 구글에서도 최근 “Inceptionism”이라는 이름으로 재미난 연구 결과를 블로그에 공개한 바 있다.
여기서는 이보다 뉴럴넷이 “어디를 집중해서 보고 있는지”를 제시한 아주 단순하고도 유용한 방법을 살펴보고자 한다. 바로 weakly-supervised localization의 시초격 되는 방법인데, localizer 모형에게 이미지에 어떤 사물이 있는지만을 학습시키면 이미지에 어떤 사물이 있는지는 물론, 이미지의 어느 위치에 그 사물이 있는지 까지 꽤나 정확하게 예측할 수 있다.
지도학습으로 학습시키긴 했지만 학습 과정에서 알려주지 않은 사물의 위치까지 학습한다는 점에서 이러한 방식을 weakly-supervised라고 이름 붙였다. 해당 논문은 재작년에 ArXiv에 올라온 것으로 발표 당시 큰 주목을 받았었다.
Architecture
이 논문에서 제시한 Weakly-supervised localizer의 구조는 매우 단순하다. 어떻게 localizer를 만드는지 그 과정을 하나하나 짚어보자.
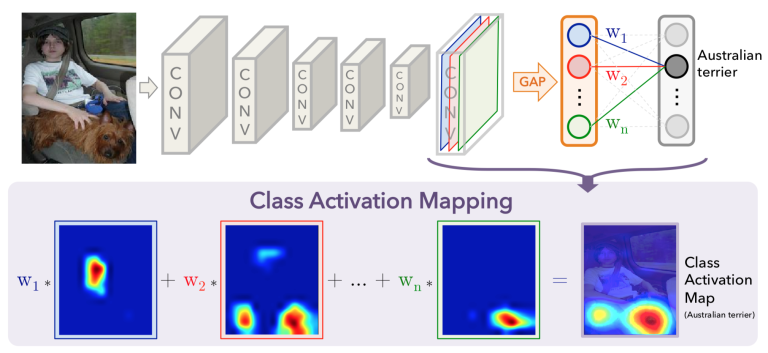
0. (Pre-trained) CNN model
CNN classifier를 가져온다. 이 classifier는 이미지를 보고 이미지에 상응하는 class label을 예측해야한다. 밑바닥부터 학습시켜도 되지만 pre-trained 모형을 사용하면 좀 더 빠르게 좋은 성능을 낼 수 있다.
가져온 CNN classifier에서 말단의 fully connected layer를 모두 제거한다. 즉 가장 깊이 있는 CONV layer가 최말단 레이어가 되도록 한다.
1. CONV layer
0.의 CNN classifier의 최말단 CONV layer 뒤에 CONV layer를 하나 추가한다. 논문에서는 1024개의 filter를 가지는 CONV layer를 추가했다. 여기서도 filter 갯수는 1024라고 가정하자.
이 레이어의 출력은 1024개의 feature map (depth=1024)이 된다.
2. Global Average Pooling (GAP)
1024개의 feature map을 크기가 1024인 벡터로 변환시킨다. 다시 말해 feature map 하나당 수치 하나로 변환시킨다.
이 과정에서 global average pooling (GAP)을 사용한다. GAP layer는 pool size가 input feature map의 크기와 같은, 즉 이미지 전체에서 딱 하나의 값(평균값)만을 pooling하는 레이어이다.
이 논문 이전에 global max pooling (GMP)를 사용한 weakly-supervised localization 방법이 공개되었었는데 GMP는 가장 activation이 강한 region의 정보만을 가져오기 때문에 사물의 경계선을 파악하는 데에 그쳤다고 한다. 사물의 위치 전체를 localization하는 데에는 모든 activation의 정보를 평균내는 GAP가 더 적합하다.
GAP layer의 출력은 각 feature map($\text{width} \times \text{height} \times 1024$)의 평균값의 벡터($1 \times 1 \times 1024$)가 된다.
3. Fully connected layer
fully connected layer를 GAP layer 뒤에 하나 추가한다.
이 dense layer의 입력은 GAP layer의 출력, 즉 크기 $1 \times 1 \times 1024$의 벡터이고 출력은 예측하려는 class label의 갯수이다. Weight matrix $W$의 모양은 $1024 \times \text{(#classes)}$가 된다.
4. Class Activation Map (CAM) 계산
1.의 CONV layer에서의 feature map과 3.의 dense layer에서의 weight $W$를 사용해서 class activation map (CAM)을 계산한다.
Label=$c$인 class의 activation map $CAM_c$는 다음과 같이 계산한다.
\[\text{CAM}\_c = \sum_{k=1}^{1024}{w_{k, c}f_k}\]여기서 $w_{k, c}$는 $k$번째 GAP 벡터에서 class $c$로 이어지는 가중치값($W$의 $k$행 $c$열 원소)이고, $f_k$는 1.에서 추가한 CONV layer의 $k$번째 feature map이다.
이렇게 구한 $CAM_c$는 해당 이미지가 클래스 $c$에 속한다고 판단내릴 때 ConvNet이 이미지의 어떤 부분을 보고있었는지의 정보를 가지고 있다.
$CAM_c$의 값이 큰 부분이 클래스 $c$에 속하는 사물의 위치라고 ConvNet이 판단내린 것이다.
응용
Weakly-supervised localization은 여러 방면에 응용될 수 있다. Semantic image segmentation을 위한 데이터를 만드는 데에도 사용될 수 있고, ConvNet이 보고있는 지점을 파악할 수 있다는 점에서 ConvNet이 이미지로부터 학습한 feature를 사람이 직관적으로 이해할 수 있도록 시각화하는 데에도 사용될 수 있다.
이미 학습된 모형을 사용해서 간단히 만들 수 있다는 큰 장점이 있어 여러 분야에 매우 쉽게 응용할 수 있다. 비록 localizer가 아닌 classifier에 비해서는 classification 성능이 떨어지지만 그 차이가 크지 않으며 localization 기능까지 덤으로 추가할 수 있다.
여기서는 직접 간단한 ConvNet을 만들어 두 가지 작업에 응용해보았다.
1) Facial emotion recognition
학습과 예측에 사용한 데이터는 다음과 같다. [source: Kaggle]
- Feature: $48 \times 48$ 크기의 흑백 얼굴 사진.
- Target: 사진 속 인물의 표정(감정). 7가지 중 하나이다(
neutral,fear,happy,sad,surprise,angry,disgust). - train set: 25120 imgs / test set: 5382 imgs
이 데이터를 학습해서 사람 표정의 어떤 부분을 보고 감정을 유추하는지를 알아보려 했다.
모형 구조와 학습에 사용한 하이퍼 파라미터는 이 노트북들[1, 2]을 참고하시길 바란다.
결과를 살펴보면 꽤 그럴듯하다.

주로 행복한 표정은 입 모양을 보고 판단하는 듯하다. 입모양이 크고 반달 모양이면 happy라고 판단할 확률이 크게 올라간다. 놀란 표정은 눈동자의 크기를 보고 판단하고 무표정은 이목구비의 전체적 형태를 보고 판단하는 듯하다.
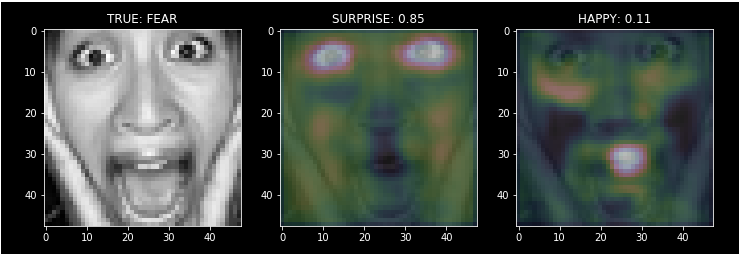
이 예시에서는 True class는 FEAR로 예측에는 실패했지만 SURPRISE라고 판단하는 것도 무리는 아닐 수 있다는 것을 보여준다. ConvNet이 무엇을 보고있는지를 주의 깊게 봐야하는 이유다.
2) Chest X-Ray (Pneumonia)
의료 이미지를 분석하는 경우엔 올바르게 질병 또는 정상상태를 분류하는 것도 중요하지만, 이미지의 어떤 부분(환부)을 보고 그런 판단을 내렸는지를 살펴보는 것이 매우 중요하다. 어디까지나 최종 판단은 의료 분야의 전문 종사자가 내리는 것인 만큼 전문가가 판단을 내리는 데에 도움이 되도록 뉴럴넷이 판단한 환부의 위치까지 표시해 준다면 더욱 유용할게다.
학습과 예측에 사용한 데이터는 다음과 같다. [source: Kaggle]
- Feature: 다양한 크기의 흉부 엑스레이 사진.
- Target: 폐렴인지 정상인지. [
PNEUMONIA/NORMAL] - train set: 5216 imgs / test set: 624 imgs
데이터 학습이 용이하도록 모든 사진을 가로 256 픽셀, 세로 200 픽셀로 resize한 후 모형에 입력시켰다. 모형 구조와 학습에 사용한 하이퍼 파라미터는 이 노트북을 참고하시길 바란다 (실수로 zero-padding을 하지 않아서 이미지의 가장자리 부분의 정보 손실이 일어났다).
81%의 꽤 높은 정확도로 test set을 올바르게 진단할 수 있었다.
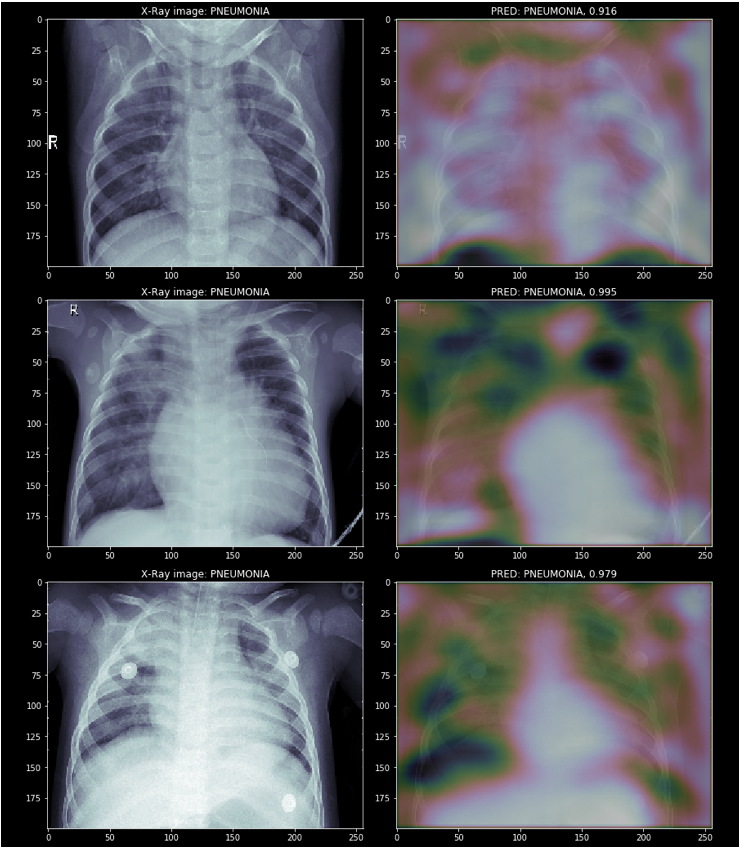
폐렴 환자의 흉부 엑스레이 사진에서는 주로 좌폐와 우폐 사이의 공간을 유심히 살펴본 것으로 보인다.
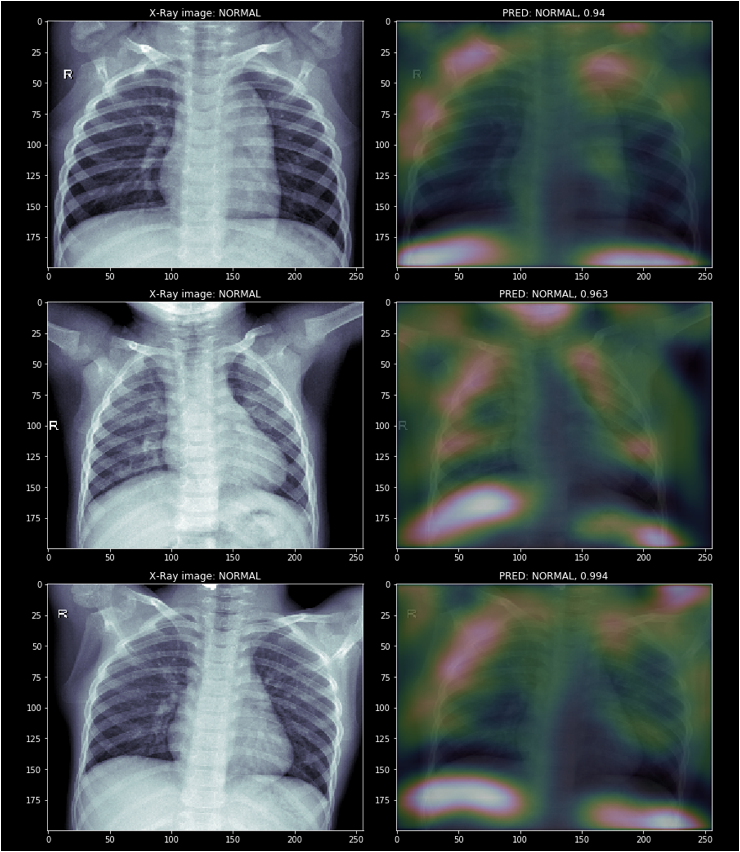
반면 정상 환자의 사진에서는 옆구리 부분의 흉골, 양쪽 폐 아래의 공간을 중요하게 본 듯 하다.
임상 전문가라면 뉴럴넷이 살펴본 위치를 보고 더 많은 아이디어를 얻을 수 있지 않을까?
참고
- Torralba et al., 2015, “Learning Deep Features for Discriminative Localization”.
- Kaggle [Facial Emotion Recognition challenge] [Chest X-ray (Pneumonia)]