인공신경망 이해하기 (3) 학습 과정 - 개요
지금까지 선형 분류기를 통해 머신러닝의 기초를 짚어보았다. 또, 일부 특수한 비선형 문제를 해결하기 위해 사용되는 커널 트릭을 아주 간단히 다루었으며 신경망 기초 이론을 이야기하면서 2층 신경망을 직접 구현해서 대부분의 비선형 문제를 해결할 수 있다는 것을 보였다.
이번 글에서는 신경망(을 포함한 머신러닝 모델)을 학습시키고 성능을 평가할 때 주의해야 할 점들에 대해 포괄적으로 다뤄보고자 한다.
Training set / Test set
앞서 과적화(overfitting) 현상에 대해 짧게 언급한 적이 있다. 모형이 데이터를 지나치게 학습한 나머지, 실제 카테고리 분류와는 관련이 없는 노이즈까지 학습해버리는 현상을 말한다.
사람 사진을 보고 남자인지, 여자인지, 혹은 둘 다 아닌지 성별을 구별해주는 모형을 학습시킨다고 해보자. 그런데 하필, 학습에 사용한 데이터에서 남자 사진은 모두 배경에 의자가 함께 찍혀있었다고 가정해보자.
제대로 학습된 모형이라면 이목구비의 생김새, 배치, 머리카락의 모양, 길이 등을 학습해서 성별을 구별할 것이다. 그러나 과적화된 모형은 배경에 의자가 있는지(카테고리 구분과 관련 없는 노이즈)를 보고 성별을 구별한다.
이러한 오버피팅 문제를 해결하기 위해서 정규화 손실항 $R(W)$을 손실함수 $L$에 추가한다는 것을 이야기했었다. 또, 정규화의 세기는 정규화 강도 (regularization strength) $\lambda$를 사용해서 조절한다는 것도 이미 이야기한 바 있다.
여기서 의문이 생긴다. 정규화를 했어도 오버피팅이 일어날 수 있다. 오버피팅이 일어나지 않았는지 어떻게 확신할 수 있을까? 다른 말로 풀어보면 이렇다: 학습시킨 분류기가 학습에 사용한 데이터 외에 다른 데이터에도 일반적으로 잘 동작한다는 것을 어떻게 확인할 수 있을까?
답은 간단하다. 직접 테스트를 해보는 수밖에 없다. 그리고 테스트를 하기 위해 우리는 가지고 있는 모든 데이터 중 일부만을 학습에 사용해야 한다. 전체 데이터를 두 조각으로 쪼개어 한 조각은 테스트 용으로 남겨둬야 한다는 말이다.

쪼갠 데이터 중 학습에 사용하는 데이터셋을 training set, 학습에는 사용하지 않고 테스트시에만 사용하는 데이터셋을 test set이라고 한다. 데이터를 쪼개는 비율은 정해져 있지는 않지만 일반적으로 train:test = 4:1, 7:3, 9:1 등을 많이 사용한다.
카테고리가 치우치지 않도록 쪼개야 한다
데이터를 쪼개는 과정에서 카테고리(라벨)가 한 데이터셋의 카테고리가 한 종류로 치우칠 수 있다. 예를 들어, 붓꽃 데이터를 training set과 test set으로 쪼개는 과정에서 training set에는 setosa 종과 versicolor 종의 데이터만, test set에는 verginica 종의 데이터만 포함될 수 있다. 이런 경우 training set, test set 모두 데이터가 불완전하므로 제대로 학습 및 테스트를 할 수가 없다.
따라서 항상 train/test 데이터셋 쪼개기를 수행할 때에는 카테고리가 한 쪽으로 치우지지 않도록 조심을 기해야 한다.
가장 간편하면서도 많이 사용하는 방법은 전체 데이터를 랜덤 셔플한 다음 train/test set을 쪼개는 것이다.

(그럴 일은 많지 않겠지만) 극히 낮은 확률로 랜덤 셔플한 후 쪼개었음에도 카테고리가 치우칠 수 있다. 이런 상황을 방지하기 위해 아예 층화 추출(stratified sampling)을 해도 된다. 층화추출법은 전체 데이터에서 각 카테고리의 비율을 유지하며 샘플링하는 기법이다. 그러나 오히려 층화추출에 의해 test set의 카테고리가 치우치는 경우가 있어서 그냥 랜덤 셔플 후 샘플링 방법을 사용하는 것이 다수이다.
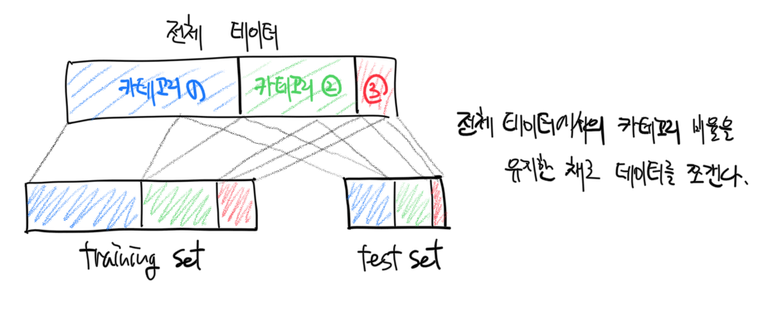
Train set은 최종 테스트(모형 성능평가)를 위해 가만히 남겨두고, training set만 가지고 놀도록 하자. 이제 학습에 사용할 데이터셋은 준비가 됐다.
하이퍼 파라미터 결정
결정해야 하는 하이퍼 파라미터
하이퍼 파라미터(hyper-parameter)는 머신러닝에서 분류기 등 모형의 학습 양상을 결정하는 중요한 수치이다. 분류기를 학습하는 과정에서 업데이트되는 파라미터(parameter; 우리가 다루었던 가중치 $W$와 편향$b$이 여기에 속한다)와 달리, 하이퍼 파라미터는 분류기를 학습하기 전에 결정되고, 학습 과정에서는 일반적으로 업데이트되지 않는다 - 그래서 hyper라고 부른다.
본격적으로 모형을 학습하기 전 우리가 정해야 하는 하이퍼 파라미터는 이런 것들이 있다.
학습률 (learning rate; $\eta$)
가장 먼저 살펴볼 하이퍼 파라미터는 학습률 $\eta$이다. 이녀석은 가중치를 업데이트할 때 등장했었다.
\[W_{new} = W_{old} - \eta \frac{\partial L}{\partial W} \\ b_{new} = b_{old} - \eta \frac{\partial L}{\partial b}\]학습률 $\eta$의 값을 크게 설정할수록 한 번의 업데이트에서 가중치값이 변화하는 폭이 커진다 (학습 속도가 빨라진다). 반대로 $\eta$의 값을 작게 설정할수록 가중치값의 변화폭이 작아진다.
‘빨리 학습한다’는 것이 듣기에는 좋아보이지만 경사하강법의 원리를 생각한다면 마냥 좋은건 아니다. $\eta$가 너무 크면 경사를 올바르게 타고 내려가지 못해서 이상한 값으로 가중치 $W$가 수렴해버릴 수 있기 때문이다.
그럼 아예 학습률을 아주 작게 설정해버리면? 학습에 너무 많은 시간이 걸려서 효율이 떨어진다. 가중치 $W$가 덜 좋은 값(non-optimum)으로 수렴해버리는 경우도 있다.
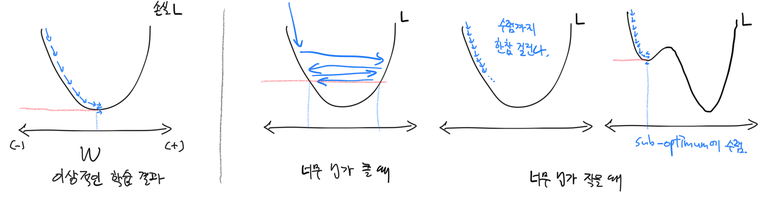
따라서 적절한 학습률을 설정하는 것이 모형 가중치의 수렴과 학습 효율에 중요하다고 하겠다.
신경망의 경우엔 처음에는 큰 학습률을 사용했다가, 일정 정도 이상 학습을 한 이후에는 학습률을 작게 조정하는 경우도 있다. 이러한 기술을 학습률 분해(learning rate decay)라고 한다. 가장 많이 사용하는 학습률 분해 테크닉은 다음과 같다.
\[\eta = \gamma^t \eta_0\]여기서 $\eta_0$은 초기에 설정한 학습률이고, $\gamma$는 [0, 1] 사이의 값, $t$는 학습 기간이다. 이 방법을 사용하면 일정 학습 기간 $t$마다 $\gamma$의 비율로 초기 학습률이 점점 ‘분해되어’ 작아진다. 일정 학습 기간마다 같은 비율로 학습률을 분해시킨다고 해서 이 방법을 step decay라고 하고 $\gamma$를 분해율(decay rate)이라 부른다.
학습률을 분해시킬 때는 분해율 $\gamma$와 분해기간 $t$를 추가로 결정해줘야 한다. 다시말해 $\gamma$, $t$도 하이퍼파라미터이다.
정규화 강도 (regularization strength; $\lambda$)
정규화의 세기를 정해주는 정규화 강도 $\lambda$도 하이퍼 파라미터다.
정규화 강도를 너무 세게 하면 데이터로부터 오는 손실이 무시될 수 있다 (데이터로부터 거의 학습을 하지 않는 underfitting 현상이 발생한다). 반대로 정규화 강도를 너무 약하게 하면 데이터의 노이즈까지 학습하는 오버피팅이 발생할 수 있다.
Dropout이라는, 신경망 모형에서 자주 사용하는 정규화 방법에선 뉴런이 특정 확률($p$)로 활성화될 수도 있고 안 될 수도 있다. 이 때 뉴런이 활성화될 확률 $p$도 학습 전 결정해야하는 하이퍼 파라미터이다. Dropout에 대해서는 다른 글에서 자세히 살펴보기로 한다.
그 외의 하이퍼 파라미터
- RNN에서 뉴런의 unfold 횟수
- CNN에서 filter 크기 및 stride 등
- 경사하강법 외의 다른 최적화 방법에 필요한 하이퍼파라미터
등등이 많지만 주로 초기 학습률 $\eta_0$, 학습률 분해율 $\gamma$ 및 분해기간 $t$, 정규화 강도 $\lambda$가 모형의 성능과 수렴에 중요한 영향을 미치기에 이 글에서는 자세히 다루지 않겠다.
좋은 하이퍼파라미터 값 찾기
validation set 만들기
결정해야하는 하이퍼 파라미터의 종류를 알았으니 이젠 그 값을 결정할 차례다. 어떤 값이 좋은 값인지는 어떻게 알 수 있을까? 다른 방법이 없다. 테스트를 해봐야 한다.
이 때 주의해야 할 것은 test set으로는 하이퍼 파라미터 테스트를 하면 안된다는 것이다. Test set으로 테스트한 하이퍼 파라미터를 사용하겠다는 것은 모형의 학습에 test set을 사용하겠다는 것과 같은 말이다. (Test set은 최종 모형의 성능 평가를 할 때, 딱 한 번만 사용해야 한다.)
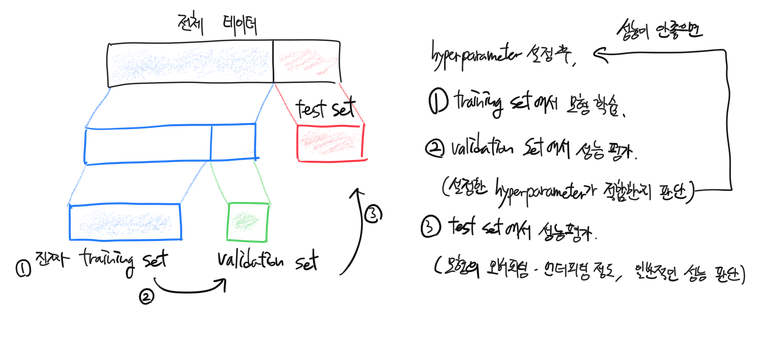
대신 training set을 다시 한번 쪼개어 하이퍼 파라미터 테스트용 데이터셋을 만들기로 한다. training set을 쪼개어 만든 하이퍼 파라미터 테스트용 데이터셋을 우리는 validation set이라고 부른다. 만든 validation set에 다양한 하이퍼 파라미터 세팅을 시험해보면서 우수한 성능을 내는 값을 선택하면 된다.
Cross-validation (CV)
데이터를 여러개의 fold로 나눈 다음 validation set을 만드는 방법도 있다.

이 방법을 k-fold cross-validation이라고 한다. 주로 3 또는 5-fold CV를 많이 사용한다.
Random search
Validation set에 시험해볼 하이퍼 파라미터 값은 어떻게 정할까? 정답: 무작위로 정한다. 그렇다고 완전 무작위로 하지는 않고 보통 다음과 같은 가이드라인을 따른다.
- 처음에는 큰 범위에서 무작위로 선택한다.
- 짧게 (1~3회 정도) 학습시킨다. 여기서 학습한다함은 가중치를 업데이트시킨다는 것이다.
- 좋은 성능을 내는 범위로 범위의 크기를 좀 줄여서 무작위로 선택한다.
- 좀 길게 (5~10회 정도) 학습시킨다.
- 범위를 조금 더 줄여서 무작위로 선택한다.
- 더욱 길게 학습시킨다.
- …
이렇게 큰 범위에서 점점 좁은 범위로 하이퍼 파라미터 값을 선택해 나가면서 좋은 값을 fine-tuning할 수 있다. 최종적인 후보 값을 선택한 후에는 손실함수값이 수렴할 때까지 끝까지 학습을 시킨다.
모형을 학습시키기 전에
모형을 학습시키는 코드를 짜기 전에 고려해야 하는 문제가 몇 가지 있다. 첫째는 학습을 시작하기 전 모형을 구성하는 파라미터($W, b$ 등) 등의 초기 값들을 어떻게 설정할 것인지에 대한 문제이고, 둘째는 모형이 올바르게 구현되었는지를 확인하는 문제이다..
초기 가중치 $W$ 설정
학습 이전 초기 가중치는 평균이 0인 임의의 작은 수로 설정하는 것이 보편적이다.
W = np.random.randn((D, K)) * .01
그런데 뉴런에 입력되는 데이터의 feature 차원에 따라 판별함수값 $s = XW + b = \sum w_ix_i + b_i$의 크기가 제각기 달라지므로, 판별함수값의 크기가 표준편차 1을 갖도록 feature 차원수 $n$으로 표준화를 해준다.
W = np.random.randn(n) * .01 / np.sqrt(n)
ReLU를 활성화 함수로 갖는 신경망층의 경우 $\div \sqrt{n/2}$로 표준화해주면 된다고 증명돼있다.
W = np.random.randn(n) * .01 / np.sqrt(n/2.)
요즘은 batch normalization(BatchNorm; BN)이라는 방식을 사용하는 것이 거의 필수가 되었다. BatchNorm에 대해서는 나중에 기회가 되면 다루기로 한다. 간단하게 정리해보자면
BN layer라는 표준화층을 모든 뉴런의 판별함수와 활성화함수 사이에 추가한다. 표준화 과정에 사용되는 파라미터도 수치적 최적화(경사하강법 등) 과정에서 업데이트되도록 한다. 시간이 지남에 따라 은닉층의 출력이 특정 방향으로 shift되는 것을 막을 수 있다.
초기 편향 $b$ 설정
초기 편향은 간단히 영벡터로 설정해준다.
b = np.random.zeros((1, K))
입력 데이터 표준화
분류기에 입력시킬 데이터(train set, test set, validation set 모두) 또한 전처리(preprocessing)를 해주어야 한다. 평균이 0, 표준편차가 1이 되도록 모든 관찰값을 정규화해준다.
x_mean = np.sum(x, axis=0) / x.shape[0] # 표본평균
x_std = np.std(x, axis=0) # 표본표준편차
x_normalized = (x - x_mean) / x_std
주의할 점은 표본평균과 표본표준편차를 계산할 때 test set, validation set을 사용하면 안된다는 것이다. 표본평균/표준편차는 training set으로만 계산해야한다. Training set에서 계산한 값들로 validation set, test set을 “표준화”해주면 된다.
초기 손실함수값 체크
손실함수에서는 두 가지 사항을 확인해야한다.
nan이 아닌 값을 반환하는가- 예상되는 값과 비슷한 값을 반환하는가
구현한 손실함수가 학습 이전에 nan을 반환하거나 예상되는 값과 다른 값을 반환한다면 구현한 코드에 문제가 있을 가능성이 크다.
초기 그라디언트 체크
분석적으로 계산한(역전파로 계산한) 그라디언트가 수치적으로 계산한 그라디언트와 일치하는지 체크한다. 수치적으로 그라디언트는 미분의 정의($f^\prime (x) = \lim_{h \to 0} \frac{f(x+h) - f(x-h)}{2h}$)를 사용해서 계산할 수 있다.
분석적 그라디언트가 수치적 그라디언트와 일치하는지의 여부는 아래 에러함수의 값으로 판단한다.
\[\frac{|f^\prime_N - f^\prime_A|}{\max(|f^\prime_N|, |f^\prime_A|)}\]여기서 $f^\prime_N$, $f^\prime_A$는 각각 수치적 그라디언트, 분석적 그라디언트이다. 그라디언트의 크기에 대한 상대적인 오류 비율이라는 의미에서 이 에러함수를 relative error라고 한다.
- Relative error 값이 1e-7 이하이면 아무 문제 없다.
- 1e-4 정도의 에러는 문제가 있을 수도 있다. ReLU처럼 미분불가능한 구간이 있는 경우엔 이정도 오류는 괜찮다. 미분불가능한 구간이 없는 경우엔 문제가 있는 에러 크기이다.
- 1e-4 이상의 에러는 문제가 있다. 분석적 그라디언트를 잘못 계산했을 수 있다.
의도적 과적화
Training set에서 작은 크기의 샘플을 추출한 다음 이걸 모형에 학습시켜서 의도적으로 과적화를 유도한다. 의도적으로 과적화시켰음에도 100%에 가까운 accuracy를 얻을 수 없다면 이 모형으로는 해당 분류 문제를 해결할 수 없다. 즉 분류기 설계가 잘못됐거나 분리가 불가능한 데이터이다.
모든 사항을 확인했다면 이제 모형을 학습시키면 된다.
모형을 학습시키는 도중에
모형을 학습시키는 중에도 모형이 데이터를 잘 학습하고 있는지 체크할 필요가 있다. 머신러닝 모형의 학습양상은 손실함수값의 수렴과 test set에서의 accuracy를 확인함으로써 파악할 수 있다.
손실함수 모니터링
가중치 $W$와 손실함수 $L$는 머신러닝 모형의 내부를 보여주는 창이다. 특히나 손실함수는 은닉층 학습양상이 직관적이지 않은(블랙박스) 신경망 기반 모형의 학습양상을 파악하는 데에 큰 도움이 된다.
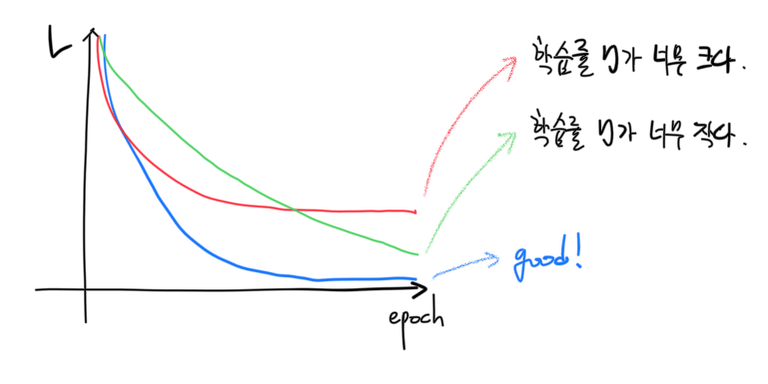
매 학습단계(epoch)에서의 손실함수값을 통해서 우리는
- 학습률이 적절히 잘 설정되었는지
- 학습이 잘 되었는지, 되다 만 것은 아닌지
등을 판단할 수 있다.
- 학습률이 너무 큰 경우 손실함수 $L$이 최적의 값이 아닌 값으로 수렴할 수 있다. 이 경우 학습률 $\eta$를 더 작게 설정해야 한다.
- 학습률이 너무 작은 경우 손실함수 $L$이 수렴하는 데에 훨씬 오랜 epoch가 필요하다. 컴퓨팅 파워와 시간이 충분하다면 epoch를 늘려보자. 그렇지 않다면 $\eta$ 값을 조금 더 크게 설정해보는 것도 방법이다.
Test set accuracy 모니터링
매 학습단계에서 training set에서의 accuracy와 test set에서의 accuracy를 비교하면
- 오버피팅이 되었는지 (정규화 강도를 조절해야 하는지)
- 언더피팅이 되었는지 (학습이 덜 되었는지, 분류기가 너무 단순하지는 않은지)
등을 판단할 수 있다.
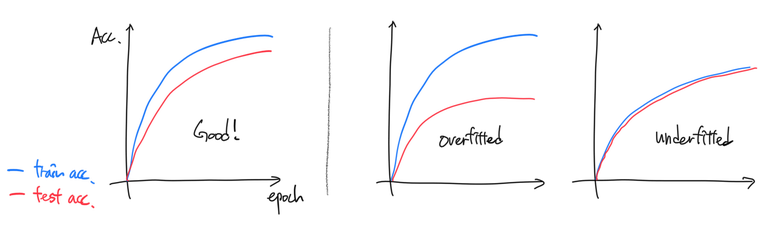
- test acc가 train acc에 비해 너무 낮다면 오버피팅의 가능성이 크다. 이 경우에는 정규화 강도 $\lambda$의 값을 키워볼 필요가 있다.
- test acc가 train acc와 거의 같다면 언더피팅을 의심해볼 수 있다. 이 경우 손실함수가 잘 수렴했는지, sub-optimal 값으로 수렴한 것은 아닌지 살펴보아야 한다. 손실함수에 문제가 없음에도 이런 현상이 나타났다면 모형이 해당 분류문제를 해결하기엔 너무 단순한 것일 수 있다. 파라미터 갯수를 늘려서 새로 모형을 만들어보자. 신경망의 경우 뉴런 수를 늘리거나 은닉층을 하나 추가해서 파라미터 갯수를 늘릴 수 있다. 물론, 그냥 문제가 쉬워서 test set에서도 성능이 좋게 나오는 걸수도 있다. 이 경우엔 두 accuracy 모두 1에 가깝게 나올 것이다.
구현
사실 이전 글에서 구현했던 분류기에는 지금까지 다뤘던 내용이 상당히 이미 코드에 포함되어 있다. 여기서는 나선형 데이터를 분류하는 2-layer NN을 구현하는 과정에서 초기 가중치 설정과 train/test set 분리, test set accuracy 모니터링을 추가로 코드로 구현해보았다.
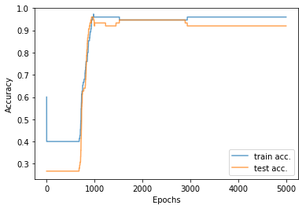
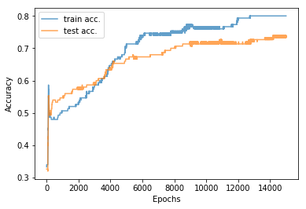
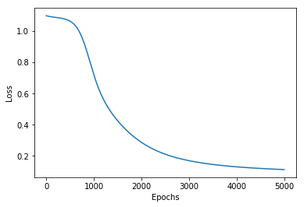
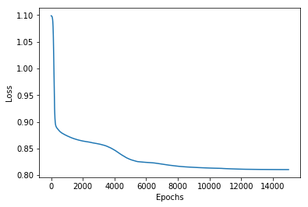
왼쪽열 그래프들은 붓꽃 분류문제에서의 accuracy, 손실함수값이고 오른쪽 그래프들은 나선형 데이터 분류문제에서의 acc와 손실함수값이다. training set만으로 학습을 마친 뒤 decision hyperplane을 training set과 test set에 각각 덧씌워 그려보았다.
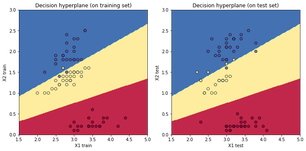
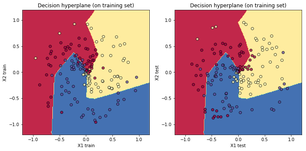
여기까지 살펴 보았듯이 머신러닝 모형을 학습시키는 데에는 왕도가 없다. 파라미터 초기화를 잘 해주고 세심히 하이퍼 파라미터를 조정한 다음 학습 과정을 유심히 지켜보며 문제가 생기지는 않는지 계속 모형을 관찰하며 어루만져 주어야 한다.
이제야 제대로 된 학습과 테스트까지 다루었다. 다음 글에서는 지금껏 자세히 다루지 않았던 내용들(경사하강법 이회의 수치적 최적화 방법, Ridge 외의 정규화 방법 등)을 차례차례 다뤄보고자 한다.
참고
- 이 글은 CS231n 강의록을 많이 참고했다. 원 강의록을 읽어보시기를 추천드린다.
- 코드는 이 노트북에 있다.